

Quickstart Guide: FMS AM3 Model
Abstract
AM3 (Donner et al., 2011), the atmospheric component of the GFDL coupled model CM3, was designed with an awareness of key emerging issues in climate science, including aerosol-cloud interactions in climate and climate change, chemistry-climate feedbacks, land and ocean carbon cycles and their interactions with climate change, and decadal prediction. It is GFDL’s first global atmospheric model to include cloud-aerosol interactions, with 20 interactive aerosol species. AM3 includes interactive tropospheric and stratospheric chemistry (85 species). AM3 uses emissions to drive its chemistry and aerosols. Its inclusion of stratospheric chemistry and dynamics will enable possible interactions between the stratosphere and troposphere on interannual scales to be included in future studies of decadal predictability. Its stratosphere has increased vertical resolution over AM2, with the uppermost level at about 1 Pascal. AM3’s improved simulation of Amazon precipitation will enhance future coupling into an earth-system model.
AM3 uses a cubed-sphere implementation of the finite-volume dynamical core. Earth’s atmosphere is represented as a cube with six rectangular faces. There is no singularity associated with the north and south poles as with the spherical representation. Computationally, the core is highly scalable and efficient at advecting the large number of tracers associated with AM3’s chemistry and aerosols.
AM3 uses physically based aerosol activitation (Ming et al., 2006) to form cloud droplets. All cloud parameterizations in AM2 were either replaced or augmented to include sub-grid distributions of vertical velocity required for these activation calculations. Sub-grid distributions of vertical velocity are included in AM3’s stratiform clouds (Golaz et al., 2011); deep convection (Donner et al., 2001, and Wilcox and Donner, 2007) represented by an ensemble of plumes with mass fluxes and vertical velocities, simple bulk microphysics, and mesoscale updrafts and downdrafts; and shallow convection after Bretherton et al. (2004, Mon. Wea. Rev.) with buoyancy sorting, entraining plumes and vertical velocity.
References:
Donner, Leo J., Bruce Wyman, Richard S Hemler, Larry W Horowitz, Yi Ming, Ming Zhao, J-C Golaz, Paul Ginoux, Shian-Jiann Lin, M Daniel Schwarzkopf, John Austin, G Alaka, W F Cooke, Thomas L Delworth, Stuart Freidenreich, C Tony Gordon, Stephen M Griffies, Isaac M Held, William J Hurlin, Stephen A Klein, Thomas R Knutson, Amy R Langenhorst, H C Lee, Y Lin, B I Magi, Sergey Malyshev, P C D Milly, Vaishali Naik, Mary Jo Nath, R Pincus, Jeff J Ploshay, V Ramaswamy, Charles J Seman, Elena Shevliakova, Joseph J Sirutis, William F Stern, Ronald J Stouffer, R John Wilson, Michael Winton, Andrew T Wittenberg, and Fanrong Zeng, July 2011: The dynamical core, physical parameterizations, and basic simulation characteristics of the atmospheric component AM3 of the GFDL Global Coupled Model CM3. Journal of Climate, 24(13), doi:10.1175/2011JCLI3955.1.
Bretherton, Christopher S., James R McCaa, Herve Grenier, 2004: A New Parameterization for Shallow Cumulus Convection and Its Application to MarineSubtropical Cloud-Topped Boundary Layers. Part I: Description and 1D Results. Monthly Weather Review, 132, 864-882.
Donner, Leo J., Charles J Seman, Richard S Hemler, and Song-Miao Fan, 2001: A Cumulus Parameterization Including Mass Fluxes, Convective Vertical Velocities, and Mesoscale Effects: Thermodynamic and Hydrological Aspects in a General Circulation model. Journal of Climate, 14(16), 3444-3463.
Golaz, J-C, M Salzmann, Leo J Donner, Larry W Horowitz, Yi Ming, and Ming Zhao, July 2011: Sensitivity of the Aerosol Indirect Effect to Subgrid Variability in the Cloud Parameterization of the GFDL Atmosphere General Circulation Model AM3.Journal of Climate, 24(13), DOI:10.1175/2010JCLI3945.1.
Ming, Yi, V Ramaswamy, Leo J Donner, and V T J Phillips, 2006: A new parameterization of cloud droplet activation applicable to general circulation models. Journal of the Atmospheric Sciences, 63(4), DOI:10.1175/JAS3686.1.
Wilcox, E M., and Leo J Donner, 2007: The Frequency of Extreme Rain Events in Satellite Rain-Rate Estimates and an Atmospheric General Circulation Model. Journal of Climate, 20(1), DOI:10.1175/JCLI3987.1
Table of Contents
- 1. Acquire the Source Code and Runscripts
- 2. Acquire the Input Datasets
- 3. Run the Model
- 4. Examine the Output
1. Acquire the Source Code and Runscripts
A zipped tar ball containing the code and scripts can be downloaded here.
This package contains code, scripts and a few small tools.
2. Acquire the Input Datasets
You may download the input data here
This file is large, 26GB after unzipping. Extract the files into a location where you have sufficient free space.
3. Run the Model
3.1. Functionality of the Sample Runscripts
This release includes a compile script and a run script for the AM3 model in the exp directory. The compile script:
- generates the mppnccombine executable, which combines individual atmospheric restart files from multiprocessor output into one netcdf file.
- generates the landnccombine executable, which combines individual land restart files from multiprocessor output into one netcdf file.
- compiles and links the model source code.
The run script:
- creates a working directory where the model will be run.
- creates or copies the required input data into the working directory.
- runs the model.
- combines distributed ouput and renames the output files using the timestamp.
Note that the directory paths and file paths are variables. They are initially set to correspond to the directory structure as it exists after extraction from the tar file, but are made variables to accommodate changes to this directory structure.
The directory path most likely to need changing is workdir. workdir is a temporary directory where the model will run. A large amount of data will be copied into the work directory, and output from the model is also written to the work directory. workdir must be large enough to accommodate all of this. The input data is approximately 20GB and model output is potentially even larger.
3.2. Portability Issues with the Sample Runscripts
If you encounter a compile error when executing the compile script, first check whether you have correctly customized your mkmf template. The scripts use the mkmf utility, which creates a Makefile to facilitate compilation. The mkmf utility uses a platform-specific template for setting up system and platform dependent parameters. Sample templates for various platforms are provided in the bin directory. You may need to consult your system administrator to set up a compilation template for your platform and ensure the locations for system libraries are defined correctly. For a complete description of mkmf see the
mkmf documentation.
3.3. layout and io_layout
3.3.1. layout
The horizontal grid of each component model is partitioned among processors according to the setting of the namelist variable “layout”. Each model has a layout variable in its namelist.
Consider a horizontal grid with 30 cells in one direction and 16 in the other. (This does not have to be rectangular longitude by latitude grid, model grids can be considered logically rectangular.) If run on 24 processors, one could set layout=6,4 The grid would be partitioned among processors as shown below. (Each asterisk represents a grid cell)
+---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=18 | pe=19 | pe=20 | pe=21 | pe=22 | pe=23 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=12 | pe=13 | pe=14 | pe=15 | pe=16 | pe=17 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=6 | pe=7 | pe=8 | pe=9 | pe=10 | pe=11 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=0 | pe=1 | pe=2 | pe=3 | pe=4 | pe=5 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+
The cubed_sphere atmosphere and land models treat each face of the cubed sphere grid as a separate grid in itself. The example above would then represent one face of the global grid. The total number of cells globally would be 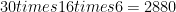

The cubed_sphere atmosphere has one restriction: It requires at least 4 grid cells in each direction, a minimum of 16 grid cells per processor.
Choice of layout has no effect on the model’s solution, but on some platforms the code’s performance can be affected.
3.3.2. io_layout
The I/O efficiency of high resolution models run on a large number of processors can be significantly impacted by the number files written. For this reason, this code allows control over the distributed output of the diagnostic and restart files.
io_layout is a namelist variable that controls the partitioning of multiple processor output among files. Each component model has its own io_layout.
Consider a model running on 24 processors with layout=6,4 as shown above. If io_o_layout were set to 3,2 the processor output would be aggregated into files as shown below.
+-------------------+-------------------+-------------------+ | | | | | | | | | | | | | pe=18 pe=19 | pe=20 pe=21 | pe=22 pe=23 | | | | | | | | | | | | | | file 3 | file 4 | file 5 | | | | | | | | | | | | | | pe=12 pe=13 | pe=14 pe=15 | pe=16 pe=17 | | | | | | | | | | | | | +-------------------+-------------------+-------------------+ | | | | | | | | | | | | | pe=6 pe=7 | pe=8 pe=9 | pe=10 pe=11 | | | | | | | | | | | | | | file 0 | file 1 | file 2 | | | | | | | | | | | | | | pe=0 pe=1 | pe=2 pe=3 | pe=4 pe=5 | | | | | | | | | | | | | +-------------------+-------------------+-------------------+
Output from a single processor cannot be divided between files. This means that io_layout must be chosen such that layout(1) and layout(2) are multiples of io_layout(1) and io_layout(2).
The output file names consist of a base name with a four digit file number appended to it. For the example above the restart files for the ice model would be:
- ice_model.res.nc.0000
- ice_model.res.nc.0001
- ice_model.res.nc.0002
- ice_model.res.nc.0003
- ice_model.res.nc.0004
- ice_model.res.nc.0005
As stated above, the cubed sphere atmosphere and land models treat each face of the global cubed sphere grid as a separate grid. From these models, one would see output files names with both the tile and processor numbers as part of the name. For example:
- atmos_coupled.res.tile1.nc.0000
- atmos_coupled.res.tile1.nc.0001
- …
- atmos_coupled.res.tile2.nc.0000
- atmos_coupled.res.tile2.nc.0001
- …
There would be a total of 30 atmos_coupled.res.* files.
Tools are provided to combine these distributed files into files of data on a single grid. The processor numbers are removed from the file names after combining. Combining of restart files is done in the run script provided, but is not required. The code has the capability of restarting with either combined or distributed restart files.
If io_layout is set to 1,1 then all processors write to a single file and the file number suffix does not appear in the file name.
3.4. Restarting and cold-starting
3.4.1. restarting
Restart files are written to a sub-directory, named RESTART, off the working directory. Information about the state of the model at the point of termination is contained in these files. Each component model and/or sub-component may have restart files. To continue a previous integration these files are put in the INPUT directory. They are read at initialization to restore the state of the model as it was at termination of the previous integration.
3.4.1. cold-starting
If a component and/or sub-component does not find its restart files in the INPUT directory then it performs a default initialization, also referred to as a cold-start. The default initialization of each component is required to be compatible with other model components, but otherwise is entirely at the discretion of the developer(s).
The atmospheric and land models typically fill the model fields with constant values for a cold-start. The result is a model state that is very flat and far away from anything scientifically interesting. As a result, a cold-started model needs to be spun-up. The spin-up time can be very long. For the land model it can be on the order of a century or more. For this reason it is recommended that the user cold-start only the atmospheric component, by omitting only atmospheric restart files and including all other restart files.
A few changes to the namelist settings are needed for a cold start. For the intrepid, a namelist file with these changes is included.
3.5. Time and calendar
Control of model time and calendar is a common source of confusion. Only a couple facts need to be understood to avoid most of this confusion. The first is how the model time and calendar are set.
When coupler.res does not exist:
current_date and calendar are as specified in coupler_nml and the namelist setting of force_date_from_namelist is ignored.
When coupler.res does exist and force_date_from_namelist=.true.:
current_date and calendar are as specified in coupler_nml.
When coupler.res does exist and force_date_from_namelist=.false.:
current_date and calendar are read from coupler.res and the namelist settings of current_date and calendar are ignored.
The second is the date which appears at the top of the diag table. This is the model initial time. It is used for two purposes.
- It is used to define a time axis for netcdf model output, the time values are since the initial time.
- It is also used in the time interpolation of certain input data. Because of this, It is recommended that it always be equal to the date that was used for current_date (in coupler_nml) in the initial run of the model and that it not change thereafter. That is, do not change it when restarting the model.
3.6. diag_table
The diagnostic output is controlled via the diagnostics table, which is named “diag_table”. Documentation on the use of diag_table comes with the release package. After extraction, it can be found here: src/shared/diag_manager/diag_table.html
3.7. data_table
The data table includes information about external files that will be read by the data_override code to fill fields of specified data. Documentation on the use of data_table comes with the release package. After extraction, it can be found here: src/shared/data_override/data_override.html
3.8. field_table
Aside from the model’s required prognostic variables; velocity, pressure, temperature and humidity, the model may or may not have any number of additional prognostic variables. All of them are advected by the dynamical code, sources and sinks are handled by the physics code. These optional fields, referred to as tracers, are specified in field_table. For each tracer, the method of advection, convection, source and sink that are to be applied to the tracer is specified in the table. In essence the field_table is a powerful type of namelist.
A more thorough description of field_table comes with the release package. After extraction, it can be found here: src/shared/field_manager/field_manager.html
3.9. Changing the Sample Runscripts
3.9.1. Changing the length of the run and atmospheric time step
By default the scripts are set up to run only one day. The run length is controlled by the namelist coupler_nml The variables months and days set the run length.
3.9.2. Changing the number of processors
By default the scripts are set up to run with the MPI library, on 288 processors. To change the number of processors, change the $npes variable at the top of the sample runscript. The processor count must be consistent with the model layouts.
To run on one processor without the MPI library, do the following:
- Set the variable $npes to 1 at the top of the sample runscript.
- Change the run command in the runscript from “mpirun -np $npes $model_executable:t” to simply “./$model_executable:t”
- Remove the -Duse_libMPI from the mkmf line in the compile script.
- Remove the -lmpi from the $LIBS variable in your mkmf template.
- Move or remove your previous compilation directory (specified as $execdir in the runscript) so that all code must be recompiled.
4. Examine the Output
You may download sample output data for comparison here.
Note that the sample output is 6.6 GB in size. Extract the files into a location where you have sufficient free space. This output was generated on the gaea system at Oak Ridge National Lab (ORNL). The file output.tar.gz contains three directories: ascii, history and restart. The ascii directory contains text output of the model including stdout and log messages. The history directory contains netCDF diagnostic output, governed by your entries in the diag_table. History and ascii files are labeled with the timestamp corresponding to the model time at the beginning of execution. The restart directory contains files which describe the state of the model at termination. To restart the model running from this state, these restart files are moved to the INPUT directory to serve as the initial conditions for your next run.