

Quickstart Guide: GFDL CM2.5 and FLOR Models
References:
Delworth, Thomas L., Anthony Rosati, Whit G Anderson, Alistair Adcroft, Venkatramani Balaji, Rusty Benson, Keith W Dixon, Stephen M Griffies, Hyun-Chul Lee, Ronald C Pacanowski, Gabriel A Vecchi, Andrew T Wittenberg, Fanrong Zeng, and Rong Zhang, April 2012: Simulated climate and climate change in the GFDL CM2.5 high-resolution coupled climate model. Journal of Climate, 25(8), doi:10.1175/JCLI-D-11-00316.1.
Vecchi, Gabriel A., Thomas L Delworth, Rich Gudgel, Sarah B Kapnick, Anthony Rosati, Andrew T Wittenberg, Fanrong Zeng, Whit G Anderson, Venkatramani Balaji, Keith W Dixon, Liwei Jia, Hyeong-Seog Kim, Lakshmi Krishnamurthy, Rym Msadek, William F Stern, Seth Underwood, G Villarini, Xiaosong Yang, and Shaoqing Zhang, November 2014: On the Seasonal Forecasting of Regional Tropical Cyclone Activity. Journal of Climate, 27(21), DOI:10.1175/JCLI-D-14-00158.1.
Table of Contents
- 1. Acquire the Source Code and Runscripts
- 2. Acquire the Input Datasets
- 3. Run the Model
- 3.5. Time and calendar
- 3.6. diag_table
- 3.7. data_table
- 3.8. field_table
- 3.9. Changing the Sample Runscripts
- 4. Known bugs
- 5. How to get help
1. Acquire the Source Code and Runscripts
A zipped tar ball containing the code and scripts can be downloaded here. This package contains code, scripts and a few tools. Model input data and sample output exist as separate files.
2. Acquire the Input Datasets
You may download the input data for CM2.5 here
You may download the input data for FLOR here
Note that the resulting tar files are sizable, approximately 24GB for the CM2.5 data. Extract the files into a location where you have sufficient free space.
3. Run the Models
3.1. Functionality of the Sample Runscripts
The scripts to compile and run the models can be found in the exp directory. They were developed and tested on the gaea machine at ORNL using the versions of system software that were default at the time of development. Both CM2.5 and FLOR run from the same source code and executable, only the input differs.
The compile script:
- compiles mppnccombine, which combines atmospheric restart files from multiprocessor distributed output into one netcdf file.
- compiles landnccombine, which combines land restart files from multiprocessor distributed output into one netcdf file.
- compiles fregrid, which interpolates data on a cubed sphere grid to a global lat-lon grid.
- compiles and links the source code.
The run script:
- creates a working directory where the model will be run.
- creates or copies the required input data into the working directory.
- runs the model.
- combines distributed ouput and renames the output files using the timestamp.
- executes mppnccombine and landnccombine to combine multiprocessor distributed output and renames the output files using the timestamp.
- executes fregrid to interpolate diagnostic output on the cubed sphere grid to a global lat-lon grid.
Note that all model output and processed model output is left in the working directory. It is not copied to permanent storage.
Also note that the directory paths and file paths are variables. They are initially set to correspond to the directory structure as it exists after extraction from the tar file, but are made variables to accommodate changes to this directory structure.
The directory path most likely to need changing is workdir. workdir is a temporary directory where the model will run. A sizable amount of data will be copied into the work directory, and output from the model is also written to the work directory. workdir must be large enough to accommodate all of this. The input data is approximately 24GB and the model output is potentially much larger.
3.2. Portability Issues with the Sample Runscripts
If you encounter a compile error when executing the compile script, first check whether you have correctly customized your mkmf template. The scripts use the mkmf utility, which creates a Makefile to facilitate compilation. The mkmf utility uses a platform-specific template for setting up system and platform dependent parameters. Sample templates for various platforms are provided in the bin directory. You may need to consult your system administrator to set up a compilation template for your platform and ensure the locations for system libraries are defined correctly. For a complete description of mkmf see the mkmf documentation.
3.3. layout and io_layout
This discussion of layouts applies only to the atmospheric and land components of the models, not the ocean or ice components. It is a repeat of what is included in GFDL’s public release of AM3.
3.3.1. layout
The horizontal grid of each component model is partitioned among processors according to the setting of the namelist variable “layout”. Each model has a layout variable in its namelist.
Consider a horizontal grid with 30 cells in one direction and 16 in the other. (This does not have to be rectangular longitude by latitude grid, model grids can be considered logically rectangular.) If run on 24 processors, one could set layout=6,4 The grid would be partitioned among processors as shown below. (Each asterisk represents a grid cell)
+---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=18 | pe=19 | pe=20 | pe=21 | pe=22 | pe=23 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=12 | pe=13 | pe=14 | pe=15 | pe=16 | pe=17 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=6 | pe=7 | pe=8 | pe=9 | pe=10 | pe=11 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+ |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | pe=0 | pe=1 | pe=2 | pe=3 | pe=4 | pe=5 | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| | | | | | | | |* * * * *|* * * * *|* * * * *|* * * * *|* * * * *|* * * * *| +---------+---------+---------+---------+---------+---------+
The cubed_sphere atmosphere and land models treat each face of the cubed sphere grid as a separate grid in itself. The example above would then represent one face of the global grid. The total number of cells globally would be 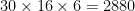

The cubed_sphere atmosphere has one restriction: It requires at least 4 grid cells in each direction, a minimum of 16 grid cells per processor.
Choice of layout has no effect on the model’s solution, but on some platforms the code’s performance can be affected.
3.3.2. io_layout
The I/O efficiency of high resolution models run on a large number of processors can be significantly impacted by the number files written. For this reason, this code allows control over the distributed output of the diagnostic and restart files.
io_layout is a namelist variable that controls the partitioning of multiple processor output among files. Each component model has its own io_layout.
Consider a model running on 24 processors with layout=6,4 as shown above. If io_layout were set to 3,2 the processor output would be aggregated into files as shown below.
+-------------------+-------------------+-------------------+ | | | | | | | | | | | | | pe=18 pe=19 | pe=20 pe=21 | pe=22 pe=23 | | | | | | | | | | | | | | file 3 | file 4 | file 5 | | | | | | | | | | | | | | pe=12 pe=13 | pe=14 pe=15 | pe=16 pe=17 | | | | | | | | | | | | | +-------------------+-------------------+-------------------+ | | | | | | | | | | | | | pe=6 pe=7 | pe=8 pe=9 | pe=10 pe=11 | | | | | | | | | | | | | | file 0 | file 1 | file 2 | | | | | | | | | | | | | | pe=0 pe=1 | pe=2 pe=3 | pe=4 pe=5 | | | | | | | | | | | | | +-------------------+-------------------+-------------------+
Output from a single processor cannot be divided between files. This means that io_layout must be chosen such that layout(1) and layout(2) are multiples of io_layout(1) and io_layout(2) respectively.
The output file names consist of a base name with a four digit file number appended to it. For the example above the restart files for the ice model would be:
- ice_model.res.nc.0000
- ice_model.res.nc.0001
- ice_model.res.nc.0002
- ice_model.res.nc.0003
- ice_model.res.nc.0004
- ice_model.res.nc.0005
As stated above, the cubed sphere atmosphere and land models treat each face of the global cubed sphere grid as a separate grid. From these models, one would see output files names with both the tile and processor numbers as part of the name. For example:
- atmos_coupled.res.tile1.nc.0000
- atmos_coupled.res.tile1.nc.0001
- …
- atmos_coupled.res.tile2.nc.0000
- atmos_coupled.res.tile2.nc.0001
- …
There would be a total of 30 atmos_coupled.res.* files.
Tools are provided to combine these distributed files into files of data on a single grid. The processor numbers are removed from the file names after combining. Combining of restart files is done in the run script provided, but is not required. The code has the capability of restarting with either combined or distributed restart files.
If io_layout is set to 1,1 then all processors write to a single file and the file number suffix does not appear in the file name.
3.4. Restarting and cold-starting
3.4.1. restarting
Restart files are written to a sub-directory, named RESTART, off the working directory. Information about the state of the model at the point of termination is contained in these files. Each component model and/or sub-component may have restart files. To continue a previous integration these files are put in the INPUT directory. They are read at initialization to restore the state of the model as it was at termination of the previous integration.
3.4.2. cold-starting
If a component and/or sub-component does not find its restart files in the INPUT directory then it performs a default initialization, also referred to as a cold-start. The default initialization of each component is required to be compatible with other model components, but otherwise is entirely at the discretion of the developer(s).
The atmospheric and land models typically fill the model fields with constant values for a cold-start. The result is a model state that is very flat and far away from anything scientifically interesting. As a result, a cold-started model needs to be spun-up. The spin-up time can be very long. For the land model it can be on the order of a century or more. For this reason it is recommended that the user cold-start only the atmospheric component, by omitting only atmospheric restart files and including all other restart files.
A few changes to the namelist settings are needed for a cold start. For the intrepid, a namelist file with these changes is included.
3.5. Time and calendar
Control of model time and calendar is a common source of confusion. Only a couple facts need to be understood to avoid most of this confusion. The first is how the model time and calendar are set.
- When coupler.res does not exist:
- current_date and calendar are as specified in coupler_nml and the namelist setting of force_date_from_namelist is ignored.
- When coupler.res does exist and force_date_from_namelist=.true.:
- current_date and calendar are as specified in coupler_nml.
- When coupler.res does exist and force_date_from_namelist=.false.:
- current_date and calendar are read from coupler.res and the namelist settings of current_date and calendar are ignored.
The second is the date which appears at the top of the diag_table. This is the model initial time. It is used for two purposes.
- It is used to define a time axis for netcdf model output, the time values are since the initial time.
- It is also used in the time interpolation of certain input data. Because of this, It is recommended that it always be equal to the date that was used for current_date (in coupler_nml) in the initial run of the model and that it not change thereafter. That is, do not change it when restarting the model.
3.6. diag_table
The diagnostic output is controlled via the diagnostics table, which is named diag_table.
Documentation on the use of diag_table comes with the release package. After extraction, it can be found in the file src/shared/diag_manager/diag_table.html.
3.7. data_table
The data_table includes information about external files that will be read by the data_override code to fill fields of specified data.
3.8. field_table
Aside from the model’s required prognostic fields, the models may or may not have any number of additional fields. These optional fields, referred to as tracers, are specified in field_table. For each tracer, the method of advection, convection, source and sink that are to be applied to the tracer is specified in the table. In essence the field_table is a powerful type of namelist.
3.9. Changing the Sample Runscripts
3.9.1. Changing the length of the run
By default the scripts are set up to run only eight days. The run length is controlled by the namelist coupler_nml The variables months and days set the run length.
3.9.2. Changing the number of processors
To change the number of processors, change the $npes variable at the top of the sample runscripts. The processor count must be consistent with the model layouts.
4. Known bugs
When compiled with the gnu compiler, version 4.7.0, both models crash with a Segmentation fault at line 897 of mpp_domains_util.inc
5. How to get help
Documentation concerning the ocean component of CM2.5 and FLOR can be found here: https://mom-ocean.github.io/docs/userguide/. This guide also provides additional documentation of the field, data and diag tables.
All inquiries regarding this release should be mailed to: GFDL.Climate.Model.Info@noaa.gov